引言
作为两只猫咪的铲屎官,有朋友觉得我对猫咪有一定的了解,于是该朋友向我咨询关于如何选择猫咪的问题,包括猫咪品种、体型、价格等一系列问题。对于他咨询的这些问题,我突然发现按平常的了解,并不能很好地回答他所提到的所有问题。于是, 作为一个有分析精神的我来说,我决定使用两份猫咪的公开数据集来进行数据分析并进行可视化。这样,有数据的支撑,我可以为我的朋友提供全方位的信息,帮助他做出明智的猫咪选择,同时为潜在的猫咪主人提供了有关如何选择猫咪的宝贵信息
明确问题
为了回答那些问题,我将以下针对各个问题,采用对应的表现方式,展示出详细的分析情况:
- 猫咪品种:了解哪些品种的猫咪在交易,树立对猫咪品种的认识,确定什么类型的猫咪符合个人的兴趣或需求,或者了解不同品种猫咪的特征和需求
- 猫咪原产地: 通过在世界地图上显示每个品种的原产地,更好地了解不同品种的分布情况和地域特点
- 猫咪的品种体型:关于不同品种猫咪的体型信息,确定对猫咪体型大小的认知,确定什么类型的猫咪符合个人的兴趣或需求
- 猫咪品种交易:这部分可以包括分析不同品种猫咪的交易情况,如哪些品种更容易找到,哪些品种更受欢迎,以及它们的价格区间
- 猫咪最高低价与均价:这一部分可以涵盖分析不同品种猫咪的价格范围,包括最高价、最低价以及均价,对有预算的有个心理保底
- 猫咪年龄:交易猫咪中的年龄分布,有助于潜在的猫咪主人更好地了解他们所选择的猫咪的照顾需求
- 影响价格的因素: 年龄、预防针、异地运费、是否纯种、是否能视频——此类因素,可以让选购者,对猫咪价格浮动有一定的了解,了解价格的波动因素,以便做出明智的选择。
问题梳理完了,接下来就是基于python进行数据清洗、分析、可视化、分析结论(个人拙见哈)
数据获取
公开数据集:cat_info.csv——200000条数据;cat_kind.csv——22条数据
import pandas as pd
# 查看数据集cat_info.csv
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
cat_info.info()
cat_info.columns # 输出Index(['地区', '商家名称', '标题', '价格', '浏览次数', '卖家承诺', '在售只数', '年龄', '品种', '预防','联系人', '联系电话', '异地运费', '是否纯种', '猫咪性别', '驱虫情况', '猫咪年龄', '能否视频', '链接'],dtype='object')
# 查看数据集cat_kind.csv
cat_kind = pd.read_csv('E:/data/cat_kind.csv', encoding='utf-8')
cat_kind.info()
cat_kind.columns # 输出Index(['品种', '参考价格', '中文学名', '别名', '祖先', '分布区域', '原产地', '体型', '原始用途', '今日用途','分组', '身高', '体重', '寿命', '整体', '毛发', '颜色', '头部', '眼睛', '耳朵', '鼻子', '尾巴','胸部', '颈部', '前驱', '后驱', '基本信息', 'FCI标准', '性格特点', '生活习性', '优点/缺点','喂养方法', '鉴别挑选'], dtype='object')获取到两份数据集的相关数据之后,便可针对对应的问题,提取数据进行分析或可视化
猫咪品种
为了解猫咪的种类都有哪些,对该数据集进行检索,顺便使用词云可视化
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
cat_kind = pd.read_csv('E:/data/cat_kind.csv', encoding='utf-8')
# 将文本中品种一列合并成一个字符串
text = ' '.join(data_kind['品种'].tolist())
# 创建一个字典,记录每个单词的频率
word_freq = {word: 1 for word in text.split()}
# 生成词云图
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path='C:/Windows/Fonts/simhei.ttf').generate(text)
# 显示词云图
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
text # 输出 '布偶猫 加菲猫 金渐层 英短蓝猫 英短蓝白 英国短毛猫 美国短毛猫 苏格兰折耳猫 银渐层 异国短毛猫 孟买猫 暹罗猫 孟加拉豹猫 缅因猫 金吉拉猫 无毛猫 高地折耳猫 曼基康矮脚猫 波斯猫 橘猫 阿比西尼亚猫 德文卷毛猫'
该数据文本较少,只有22条数据,每条数据对应一种类型的猫咪; 通过可视化,猫咪的种类赫然呈现,可以根据自己的兴趣去了解猫咪品种(^o^)/~
猫咪原产地
了解猫咪的品种,同时可以了解猫咪的原产地,通过在世界地图上显示每个品种的原产地,更好地了解不同品种的分布情况和地域特点
通过地图可视化展现猫咪原产地分布:
import pandas as pd
import folium
from geopy.geocoders import Nominatim
cat_kind = pd.read_csv('E:/data/cat_kind.csv', encoding='utf-8')
# 从数据中提取不同品种猫猫的原产地信息
cat_origins = cat_kind[['品种', '原产地']].dropna().drop_duplicates()
# 创建一个地图对象
m = folium.Map(location=[0, 0], zoom_start=2)
# 初始化地理编码器
geolocator = Nominatim(user_agent="cat_origin_geocoder")
# 在地图上添加标记
for index, row in cat_origins.iterrows():
brand_info = f"品种: {row['品种']}, 原产地: {row['原产地']}"
# 尝试地理编码获取经纬度坐标
location = geolocator.geocode(row['原产地'])
if location:
folium.Marker([location.latitude, location.longitude], tooltip=brand_info).add_to(m)
# 在Jupyter Notebook中显示地图
m
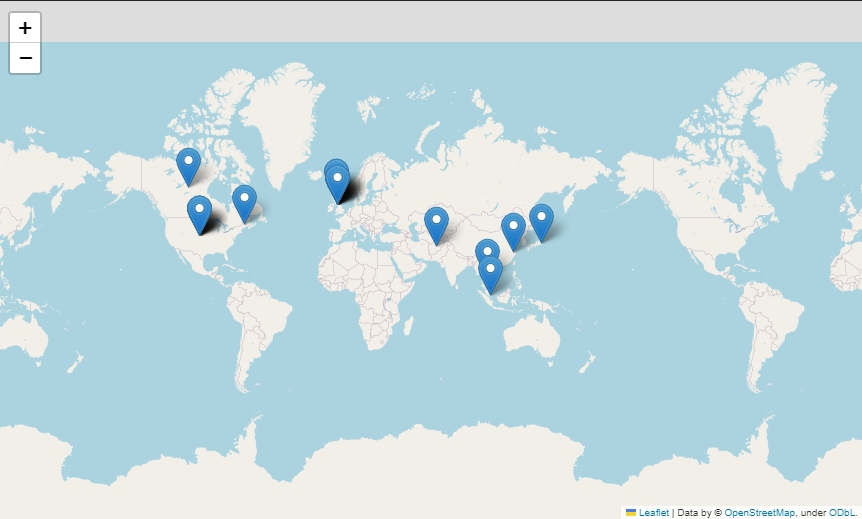
地图可视化图像交互数据读取,英美,加拿大等国是大多数猫猫品种们的原产地,每个国家也有对应的猫咪品种,通过数据的统计,橘猫是世界各地都有的,大橘还真是遍布全球哈。
猫咪品种体型
不同品种的猫咪的体型是有差异的,不同的人喜欢不同的体型大小的猫咪,这时候猫咪的体型分布可以作为参考
import pandas as pd
import matplotlib as plt
cat_kind = pd.read_csv('E:/data/cat_kind.csv', encoding='utf-8')
# 统计不同猫咪品种的数量
cat_kinds_count = cat_kind["品种"].nunique()
# 选择并展示指定列
cat_kinds_info = cat_kind[selected_columns]
# 按照体型分类,计算每个体型内各个品种的数量
cat_counts = cat_kinds_info.groupby(['体型', '品种']).size().unstack(fill_value=0)
# 创建堆叠条形图
ax = cat_counts.plot(kind='bar', stacked=True, figsize=(12, 6))
plt.xlabel('体型',color='white')
plt.ylabel('数量',color='white')
plt.title('不同猫咪体型内各品种的分类')
plt.legend(title='品种', loc='upper right', bbox_to_anchor=(1.15, 1))
plt.show()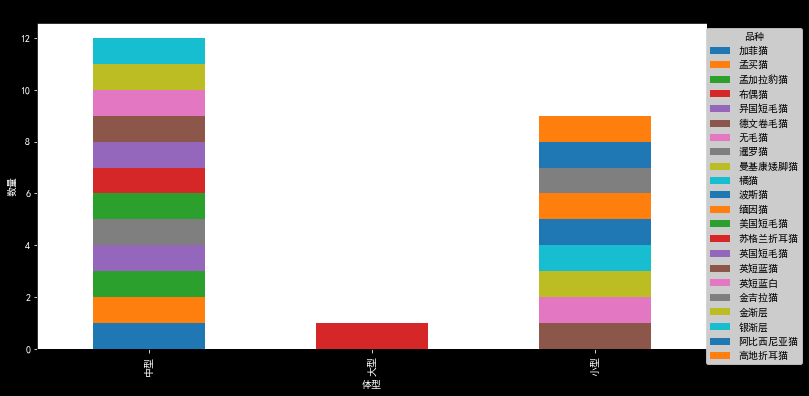
从上图可视化可看出,体型为中型的猫咪品种最多,多数品种猫咪的体型还是中型的哈,而大型体型的则最少;
震惊的是,生活中常说的“大橘为重”的橘猫,居然是属于小型品种的猫咪!!而布偶猫确实归类为大型体型的猫咪,还真是刷新了我原有的观念,大橘!!你要自重!!!你可是小型猫!!!
猫咪品种交易
了解完猫咪品种和体型大小,想了解主要都是哪些品种在交易呢?用可视化展现各品种猫咪的占比
import pandas as pd
import plotly.express as px
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
# 统计各品种的交易数量
cat_counts = cat_info['品种'].value_counts().reset_index()
cat_counts.columns = ['品种', '交易数量']
# 创建矩形树图
fig = px.treemap(cat_counts,
path=['品种'],
values='交易数量',
color='交易数量',
color_continuous_scale='Viridis',
title='不同品种猫的交易占比')
# 显示图表
fig.show()
surprise~~ 橘猫是被交易最多呀,看来之前原产地说橘猫分布在世界各地,换句话可以理解为橘猫数量最多,还是有原因的,大橘的认可度还是很不错的!
猫咪最高低价与均价
对于买猫的人来说,除了自身喜爱之外,通常还会考虑性价比的问题,有时候去选择猫咪的时候,这个度量标准还是有的,有预算且想了解下各个品种的价格分布和价值范围还是很有必要的。
import pandas as pd
import matplotlib.pyplot as plt
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
# 数据预处理
cat_info = cat_info.dropna(subset=['价格'])
cat_info['价格'] = pd.to_numeric(cat_info['价格'], errors='coerce')
# 统计不同品种猫咪的价格范围
price_stats = cat_info.groupby('品种')['价格'].agg(['min', 'max', 'mean']).reset_index()
price_stats_sorted = price_stats.sort_values('mean', ascending=False)
# 绘制价格范围的可视化图表
plt.figure(figsize=(12, 6))
# 使用红色表示均价
plt.bar(price_stats_sorted['品种'], price_stats_sorted['mean'], label='均价(白色数值)', color='r', edgecolor='k')
# 使用蓝色表示价格范围
plt.bar(price_stats_sorted['品种'], price_stats_sorted['max'] - price_stats_sorted['min'],
bottom=price_stats_sorted['min'], label='最高价与最低价', color='b', alpha=0.5, edgecolor='k')
plt.xlabel('猫咪品种')
plt.ylabel('价格')
plt.title('不同品种猫咪的价格范围')
plt.xticks(rotation=90)
plt.legend()
# 在图上添加均价、最高价和最低价数值(去掉小数点后两位)
for i, row in price_stats_sorted.iterrows():
mean_price = int(row['mean'])
min_price = int(row['min'])
max_price = int(row['max'])
plt.text(row['品种'], mean_price, f'{mean_price}', ha='center', va='bottom', fontsize=10, color='white')
plt.text(row['品种'], max_price, f'{max_price}', ha='center', va='top', fontsize=10, color='black')
plt.text(row['品种'], min_price, f'{min_price}', ha='center', va='bottom', fontsize=10, color='black')
plt.show()
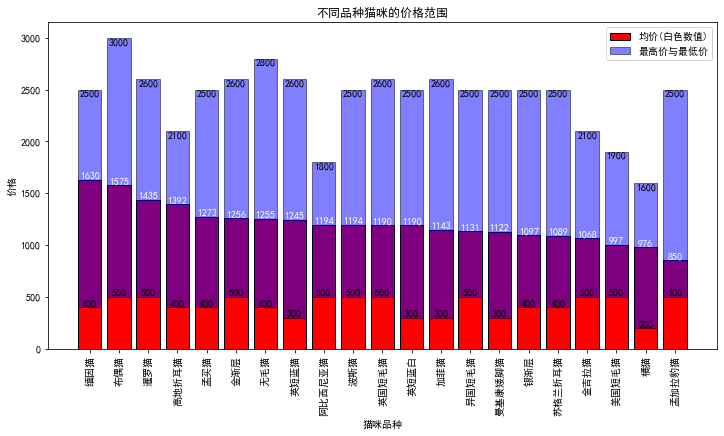
上图展现的便是猫咪的最高,最低价格,中间白色数据则为猫咪的均价, 买的时候有个平均价格参考,心中有个数才好把握吧
猫咪年龄
交易的猫咪一般年龄也是不同的,大多数时候是什么年龄段的猫咪在售卖呢?
import pandas as pd
import matplotlib.pyplot as plt
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
# 将年龄分组到不同的时间段
cat_info['年龄分组'] = pd.cut(cat_info['猫咪年龄'], bins=age_bins, labels=age_labels, right=False)
# 统计各时间段的猫咪数量
age_group_counts = cat_info['年龄分组'].value_counts().reindex(age_labels, fill_value=0)
# 创建直方图
plt.figure(figsize=(10, 6))
bars = age_group_counts.plot(kind='bar', color='skyblue')
plt.title('猫咪年龄分布')
plt.xlabel('年龄分组')
plt.ylabel('数量')
plt.xticks(rotation=0)
# 在每个柱形上显示数值
for bar in bars.patches:
plt.annotate(f'{bar.get_height()}', (bar.get_x() + bar.get_width() / 2, bar.get_height()), ha='center', va='bottom')
plt.show()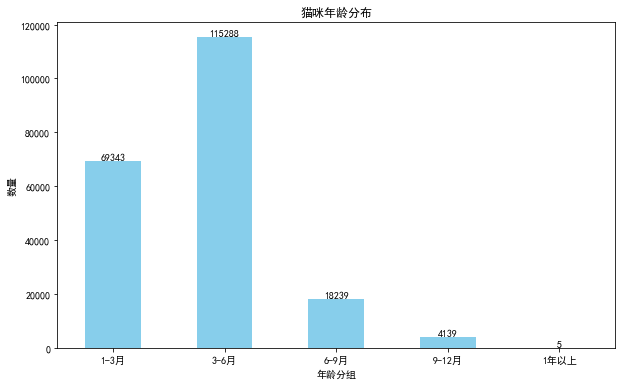
从数据上看,猫咪3~6月之间的是最多数的,偏小的猫咪确实也比较可爱,这时候通过交易来到新主人的身边,也很好熟悉,静静地陪着长大^_^
影响价格因素
影响猫咪的价格的可能因素有哪些呢?
浏览热度与价格
浏览次数一定程度上反映了猫猫的热度,同过对其分析,判断是否有线性关系
import pandas as pd
import matplotlib.pyplot as plt
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
# 1. 数据预处理
# 删除包含缺失价格和浏览次数的行
cat_info = cat_info.dropna(subset=['价格', '浏览次数'])
cat_info['价格'] = pd.to_numeric(cat_info['价格'], errors='coerce')
cat_info['浏览次数'] = pd.to_numeric(cat_info['浏览次数'], errors='coerce')
# 2. 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(cat_info['浏览次数'], cat_info['价格'], alpha=0.5)
plt.title('浏览次数与价格的关系')
plt.xlabel('浏览次数')
plt.ylabel('价格')
plt.show()
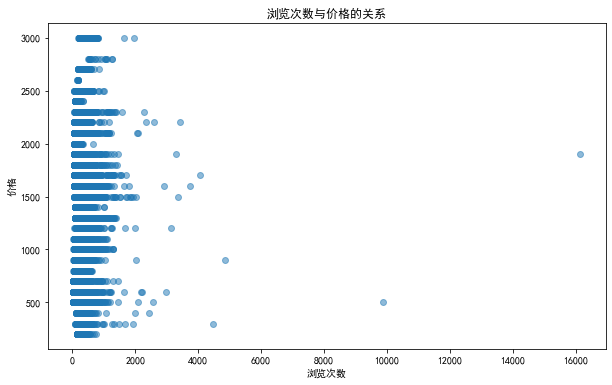
从散点图上看浏览次数与价格并不存在相关性;
其它因素分析代码
那就从其它方面进行分析,通过查看字段选取:年龄、预防、异地运费、是否纯种、是否视频进行相关性分析
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
cat_info.info()
cat_info.columns # 输出Index(['地区', '商家名称', '标题', '价格', '浏览次数', '卖家承诺', '在售只数', '年龄', '品种', '预防','联系人', '联系电话', '异地运费', '是否纯种', '猫咪性别', '驱虫情况', '猫咪年龄', '能否视频', '链接'],dtype='object')
可视化分析-箱线图: 将多个箱线图放在同一个图表中,通过比较它们之间的数据分布差异来研究不同变量之间的关系
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
cat_info = pd.read_csv('E:/data/cat_info.csv', encoding='gbk')
# 创建一个新的DataFrame用于存储处理后的数据
processed_data = cat_info.copy()
# 对 processed_data 应用处理操作
processed_data['年龄'] = processed_data['年龄'].astype(str).str.extract('(\d+)').astype(float)
processed_data['预防'] = processed_data['预防'].astype(str).str.extract('(\d+)').astype(float)
processed_data['异地运费'] = processed_data['异地运费'].map({'包运费!签协议!': 1, '不包邮!': 0})
processed_data['是否纯种'] = processed_data['是否纯种'].map({'是': 1, '否': 0})
processed_data['能否视频'] = processed_data['能否视频'].map({'可视频看猫咪': 1, '不可视频看猫咪': 0})
# 创建指定列的箱线图
def create_boxplot(data, column, title, custom_labels=None):
plt.figure(figsize=(10, 6))
plt.title(title, fontsize=15)
boxplot = data.boxplot(column=['价格'], by=column)
plt.ylabel('价格')
plt.xlabel(column)
plt.suptitle('') # 禁止显示默认标题
if custom_labels is not None:
# 设置自定义x轴刻度标签
xtick_labels = [custom_labels[val] for val in custom_labels.keys()]
plt.xticks(range(1, len(custom_labels) + 1), xtick_labels)
plt.show()
# 自定义标签'预防' 列
custom_labels_for_预防 = {
1: '0预防针',
2: '1预防针',
3: '2预防针',
4: '3预防针'
}
# 自定义标签'异地运费' 列
custom_labels_for_异地运费 = {
0: '不包邮',
1: '包运费签协议'
}
# 自定义标签'是否纯种' 列
custom_labels_for_是否纯种 = {
0: '否',
1: '是'
}
# 自定义标签 '能否视频' 列
custom_labels_for_能否视频 = {
0: '不可视频看猫咪',
1: '可视频看猫咪'
}
# 箱线图的列和各自的标题
boxplot_info = [
('年龄', '价格与年龄的关系', None), # 无自定义标签
('预防', '价格与预防的关系', custom_labels_for_预防),
('异地运费', '价格与异地运费的关系', custom_labels_for_异地运费),
('是否纯种', '价格与是否纯种的关系', custom_labels_for_是否纯种),
('能否视频', '价格与能否视频的关系', custom_labels_for_能否视频)
]
# 使用处理过的数据为每个指定列创建箱线图
for column, title, custom_labels in boxplot_info:
create_boxplot(processed_data, column, title, custom_labels)
年龄与价格
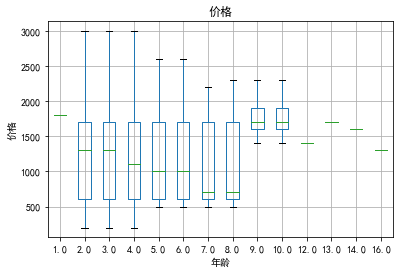
从多个箱线图上看,猫咪年龄在9月份之后的,价格明显在1300往上,而1-9月份大的猫咪的价格分布则500以下也有,大部分分布在500-1700,分布有明显的不同;由此可见,猫咪的年龄对于价格有一定的影响,是猫咪价格的一个影响因素。
预防与价格
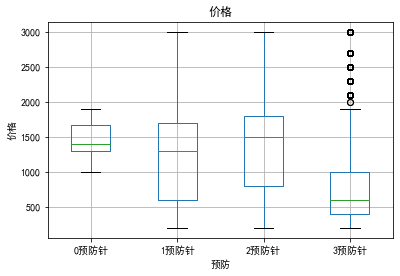
通过箱线图的分布来看,其分布明显不同,1~2针的猫咪价格分布几乎差不多;惊奇的是3针的价格反而较低,由此可见,预防针次数也是与价格相关的,也是一个影响因素
异地运费与价格
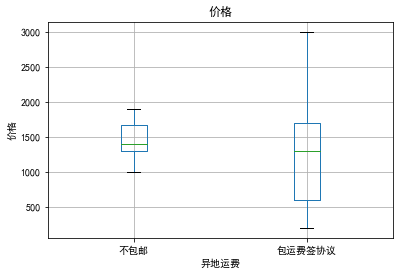
包含运费的猫咪(包运费)价格更高,这是因为运费的成本被计入了猫咪的售价
是否纯种与价格
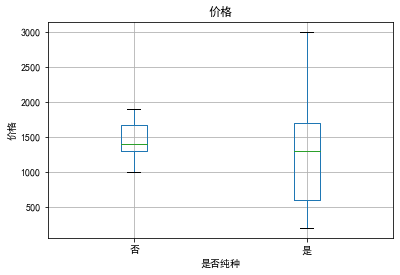
纯种猫的价格明显高于非纯种的,这可能是因为纯种猫通常更受欢迎并被认为具有更高的价值,因此也成为了影响猫咪价格的因素。
能否视频与价格

能够提供视频查看的猫咪(可视频观看猫咪)的价格分布似乎更广,这表明商家提供视频查看服务的通常有更多的价格策略或不同类型的猫咪,因此也是猫咪价格的影响因素。
总结
通过以上箱线图的分析, 影响价格的因素猫猫价格的相关因素有年龄,预防次数,邮费,是否纯种,能否看猫猫视频 。
结语
通过对猫咪数据的深入分析,我们为潜在的猫咪主人提供了有关如何选择猫咪的宝贵信息。我们了解到不同品种的猫咪拥有各自独特的特征和需求,而这些特征往往会影响价格。我们还探讨了年龄、疫苗接种、运输、纯种与否以及视频展示等因素对价格的影响,为购买者提供了更全面的了解。
选择一只猫咪是一个重要的决策,它将成为您的伴侣和家庭一部分。我们希望本研究能够帮助您更好地理解选择猫咪的因素,以便做出明智的选择,以满足您的兴趣和需求。同时,我们鼓励您进一步研究和咨询专业兽医和养猫专家,以确保您的新家庭成员能够获得最好的照顾。
无论您最终选择了哪种猫咪,愿您与您的新伙伴共度美好时光,建立深厚的友情❤❤❤❤❤❤❤❤
附录
数据集: https://bevis.lanzouq.com/ir6N71cashfe
数据集来自和鲸社区:https://www.heywhale.com/mw/dataset/608e9c6a38a59800175520f8
数据来自猫咪交易网:http://www.maomijiaoyi.com/




