引言
在当今数字化时代,网络安全攻击已成为一个日益严重的问题。了解各种攻击类型和模式对于有效预防和应对网络威胁至关重要。在逛kaggle社区的时候,发现数据集:’cybersecurity_attacks.csv’,同过介绍和字段查看,发现它经过精心制作,真实地再现了网络安全攻击的历史,这个数据集为我们提供了一个理想的场所,进行各种分析任务和研究,了解网络安全攻击的特征和趋势。
通过使用这个网络安全攻击数据集,可进行多个层面的评估和分析。可以生成热图来可视化攻击活动的分布和强度,探索不同攻击特征和模式,以了解攻击者的策略和技术。可以对攻击类型进行分类和分析,以便更好地了解不同类型攻击的特点和威胁级别。
这篇博文将针对这个令人兴奋的数据集展开数据分析,探索网络安全攻击的潜在模式和趋势。希望通过对数据的深入挖掘,了解有关网络安全保护和防御的有用见解,并为构建更加安全的数字环境贡献一份力量。让我们一起开始这个令人兴奋的数据探险之旅吧!
数据集来源:https://www.kaggle.com/datasets/teamincribo/cyber-security-attacks/data
以下过程使用 jupyter notebook实现,代码均无使用print输出, Jupyter具有交互式和文档化的特点 , 即使您没有使用print函数,执行单元格时, Jupyter Notebook的默认行为,仍将在屏幕上打印每个变量的值以元组形式输出,使用其他实现方式的小伙伴需要使用print输出
数据信息获取
import pandas as pd
# 加载数据集csv文件
file_path = 'E:\data\cybersecurity_attacks.csv'
dataset = pd.read_csv(file_path)
# 通过查看前五行,查看数据字段有哪些
dataset.head()读取csv内容有如下:
| Timestamp | Source IP Address | Destination IP Address | Source Port | … |
|---|---|---|---|---|
| 0 | 2023/5/30 6:33 | 103.216.15.12 | 84.9.164.252 | Qui natus odio asperiores nam. Optio nobis ius… |
| 1 | 2020/8/26 7:08 | 78.199.217.198 | 66.191.137.154 | Aperiam quos modi officiis veritatis rem. Omni… |
| 2 | 2022/11/13 8:23 | 63.79.210.48 | 198.219.82.17 | Perferendis sapiente vitae soluta. Hic delectu… |
| 3 | 2023/7/2 10:38 | 163.42.196.10 | 101.228.192.255 | Totam maxime beatae expedita explicabo porro l… |
| 4 | 2023/7/16 13:11 | 71.166.185.76 | 189.243.174.238 | Odit nesciunt dolorem nisi iste iusto. Animi v… |
字段还挺多的哈,25个
这个数据集包含了 40,000 条网络流量记录,每条记录有 25 个字段。这些字段包括时间戳、源 IP 地址、目的 IP 地址、源端口、目的端口、协议类型、数据包长度、数据包类型、流量类型、负载数据等。一些与安全相关的字段,如恶意软件指标、异常分数、警报/警告、攻击类型、采取的行动等。
针对此类数据,先分析以下三个方面:
- 热图:可视化源和目的IP地址或端口的频率。
- 攻击特征与类型:识别可能表明恶意活动的模式,例如短时间内多次尝试连接;分析攻击类型与严重级别;
- 流量类型:对流量类型(HTTP、DNS等)进行分类,了解使用模式。
数据清理
老样子,开始数据分析前必做的事:确保数据集没有重复或不相关的条目。
清理重复数据
# 删除重复行
dataset_cleaned = dataset.drop_duplicates()
# 查看删除行
original_shape = dataset.shape[0]
cleaned_shape = dataset_cleaned.shape[0]
rows_removed = original_shape - cleaned_shape
original_shape, cleaned_shape, rows_removed # jupyter 输出 (40000, 40000, 0) 元组形式
print(original_shape,cleaned_shape,rows_removed) # print输出 40000 40000 0
通过对删除重复行前后的行数对比,40000条数据无变化,看来数据集作者是已经清洗过的了^_^
特征提取
关注以下几个主要特征:
- Source IP Address 和 Destination IP Address(源IP和目的IP): 是网络通信中非常基本的信息,它们用于识别发送和接收方。通过将这些信息可视化为热图,可以更好地了解网络流量的分布情况。
- Timestamp(时间戳): 时间戳表示网络通信发生的时间点,可以帮助我们发现和识别攻击模式。例如,如果我们发现某个时间段内有大量的数据包发送,那么可能表示有人正在对系统进行攻击
- Traffic Type(流量类型): 用于了解网络通信的性质。不同类型的流量(例如HTTP、FTP等)有着不同的特征和限制条件。通过对流量类型的分类和分析,了解网络通信的本质,从而有针对性地采取措施来保护系统和数据的安全。
数据可视化
创建热图
创建几个热图,分别表示“源 IP 地址”和“目的 IP 地址”的频率。
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备,将结果存储在两个不同的数据帧
source_ip_counts = dataset_cleaned['Source IP Address'].value_counts().reset_index().rename(columns={'index': 'Source IP Address', 'Source IP Address': 'Count'})
destination_ip_counts = dataset_cleaned['Destination IP Address'].value_counts().reset_index().rename(columns={'index': 'Destination IP Address', 'Destination IP Address': 'Count'})
# 创建热力图
fig, axs = plt.subplots(1, 2, figsize=(20, 10))
# 源ip热力图
sns.heatmap(source_ip_counts.pivot(columns='Source IP Address', values='Count').fillna(0), annot=True, cmap='coolwarm', ax=axs[0])
axs[0].set_title('Source IP Address Frequency')
# 目的ip热力图
sns.heatmap(destination_ip_counts.pivot(columns='Destination IP Address', values='Count').fillna(0), annot=True, cmap='coolwarm', ax=axs[1])
axs[1].set_title('Destination IP Address Frequency')
plt.show() # 输出:MemoryError: Unable to allocate 11.9 GiB for an array with shape (40000, 40000) and data type float64
哦吼,有意思,MemoryError……,是的,没错,数据计算机无法为其分配足够的空间,导致内存溢出错误;
为了解决这个问题,我们可以采取以下几种方法:
- 缩小数据范围: 选择数据集的一个子集进行分析。
- 聚合数据: 只考虑最频繁出现的 IP 地址。
先尝试第二种方法,只考虑出现次数最多的 IP 地址。这样,就可以减少数据的规模,同时仍能获取有用的信息。
创建简化版的热图
# 前10个最常见的源IP地址和目的IP地址
top_10_source_ip = source_ip_counts.nlargest(10, 'Count')
top_10_destination_ip = destination_ip_counts.nlargest(10, 'Count')
# 创建简单热力图
fig, axs = plt.subplots(1, 2, figsize=(20, 10))
# Top 10源IP地址热图
sns.barplot(x='Count', y='Source IP Address', data=top_10_source_ip, ax=axs[0], palette='coolwarm')
axs[0].set_title('Top 10 Source IP Address Frequency')
# top 10目的IP地址热图
sns.barplot(x='Count', y='Destination IP Address', data=top_10_destination_ip, ax=axs[1], palette='coolwarm')
axs[1].set_title('Top 10 Destination IP Address Frequency')
plt.show() # 正常输出热力图

这出了两个简化版的热图,分别表示出现次数最多的前 10 个“源 IP 地址”和“目的 IP 地址”。
热力图中的颜色表示频率的大小,较深的颜色代表较高的频率。通过观察热力图,可以得出以下分析结果:
- 前10个最常见的源IP地址:根据柱状图的高度,可以看出哪些IP地址是数据中最常见的来源。这可能有助于识别哪些IP地址发送了大量的网络流量或请求。
- 前10个最常见的目的IP地址:类似地,通过目的IP地址的频率,可以确定哪些IP地址是数据中最常见的目标。这可能有助于发现接收大量流量或请求的主机。
通过分析这些数据,可以发现网络流量的热点区域,识别潜在的异常行为或攻击。此外,还可以帮助网络管理员优化网络结构、检测潜在的安全风险,以及进行其他网络运维和安全方面的决策。然而,具体的分析结果仍然需要根据实际情况和进一步的上下文来解读和应用。
# 此段代码是针对个人jupyter的背景主题而做的,为了更好看清可视化图像
# 设置标题的颜色为白色
axs[0].set_title('Top 10 Source IP Address Frequency', color='white')
axs[0].set_xlabel('Count', color='white')
axs[0].set_ylabel('Source IP Address', color='white')
axs[1].set_title('Top 10 Destination IP Address Frequency', color='white')
axs[1].set_xlabel('Count', color='white')
axs[1].set_ylabel('Destination IP Address', color='white')
# 设置坐标轴标签的颜色为白色
axs[0].tick_params(axis='x', colors='white')
axs[0].tick_params(axis='y', colors='white')
axs[1].tick_params(axis='x', colors='white')
axs[1].tick_params(axis='y', colors='white')
分析攻击特征与类型
攻击特征
为了分析可能的攻击特征,观察在短时间内是否有多次连接尝试。这通常是暴力破解或其他类型攻击的一个信号。
# Timestamp列转换为datetime格式
dataset_cleaned['Timestamp'] = pd.to_datetime(dataset_cleaned['Timestamp'])
# 按时间戳和源IP地址排序
dataset_cleaned.sort_values(['Source IP Address', 'Timestamp'], inplace=True)
# 计算同一源IP地址的每一行与前一行之间的时间差
dataset_cleaned['Time Difference'] = dataset_cleaned.groupby('Source IP Address')['Timestamp'].diff()
# 将时差转换为秒,以便于分析
dataset_cleaned['Time Difference (s)'] = dataset_cleaned['Time Difference'].dt.total_seconds()
# 过滤掉时间差小于某个阈值的行(10秒)
suspicious_activity = dataset_cleaned[dataset_cleaned['Time Difference (s)'] < 10]
# 统计每个源IP地址的可疑活动数量
suspicious_counts = suspicious_activity['Source IP Address'].value_counts().reset_index().rename(columns={'index': 'Source IP Address', 'Source IP Address': 'Count'})
# 显示10个最常见的可疑源IP地址
top_10_suspicious = suspicious_counts.nlargest(10, 'Count')
top_10_suspicious # 输出Source IP Address Count 仅仅出现字段名 无数据
通过输出可以发现:在这个数据集中没有发现在短时间内重复出现的“源 IP 地址”,这意味着没有明显的恶意攻击活动。
攻击类型
# 查看攻击类型
attack_types = dataset['Attack Type'].value_counts()
attack_types
# 输出,每种攻击类型的频率大致相当,都在13000多次事件左右
DDoS 13428
Malware 13307
Intrusion 13265
Name: Attack Type, dtype: int64由此得出,数据集中有三种主要的攻击类型:
- DDoS(分布式拒绝服务攻击): 这类攻击涉及多个系统联合攻击单一目标,导致目标系统的服务中断或崩溃。
- Malware(恶意软件): 这涉及到恶意软件,例如病毒、蠕虫、特洛伊木马等,它们会侵入并可能损害系统。
- Intrusion(入侵): 这涉及未经授权的访问,旨在窃取敏感数据或破坏系统。
针对一下两点分析:
- 严重性级别:分析每种攻击类型的严重性级别分布。
- 网络段影响:查看哪些网络段受到了最多的攻击。
# 设置字体颜色为白色,个人的黑色背景只能调节颜色提高可视化效果,白色背景可不调,默认为黑色字体
plt.rcParams.update({'text.color': 'white', 'axes.labelcolor': 'white', 'xtick.color': 'white', 'ytick.color': 'white'})
# 绘制图表,分析每种攻击类型的严重性级别分布
plt.figure(figsize=(12, 7))
sns.countplot(x='Attack Type', hue='Severity Level', data=dataset, palette='muted')
plt.title('Distribution of Severity Levels by Attack Type')
plt.xlabel('Attack Type')
plt.ylabel('Count')
# 获取图例对象
legend = plt.legend(title='Severity Level', title_fontsize='14')
# 设置图例文字的颜色为黑色
for text in legend.get_texts():
text.set_color('black')
# 设置标题的字体颜色
legend.get_title().set_color('black')
plt.tight_layout()
plt.show()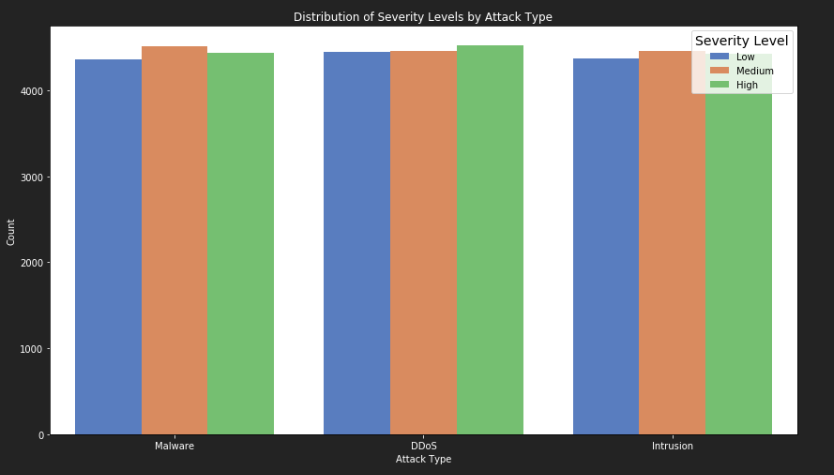
从上图中,我们可以得出以下结论:
- Malware 攻击:这类攻击主要是中等,低高级攻击较少。
- DDoS 攻击:这类攻击的严重性级别分布相对均匀,但高级攻击略多中低级攻击。
- Intrusion 攻击:这类攻击中高级较低级相对多一些
柱形图没有特别起伏大的柱状,但是高低依旧清晰可见,如此结论足矣
# 分析哪些网络段受到了最多的攻击,绘制攻击在不同网段的分布
plt.figure(figsize=(10, 6))
sns.countplot(x='Network Segment', hue='Attack Type', data=dataset, palette='pastel')
plt.title('Distribution of Attack Types by Network Segment')
plt.xlabel('Network Segment')
plt.ylabel('Count')
# 获取图例对象
legend = plt.legend(title='Attack Type', title_fontsize='14')
legend.get_title().set_color('black')
# 设置图例文字的颜色为黑色
for text in legend.get_texts():
text.set_color('black')
plt.tight_layout()
plt.show()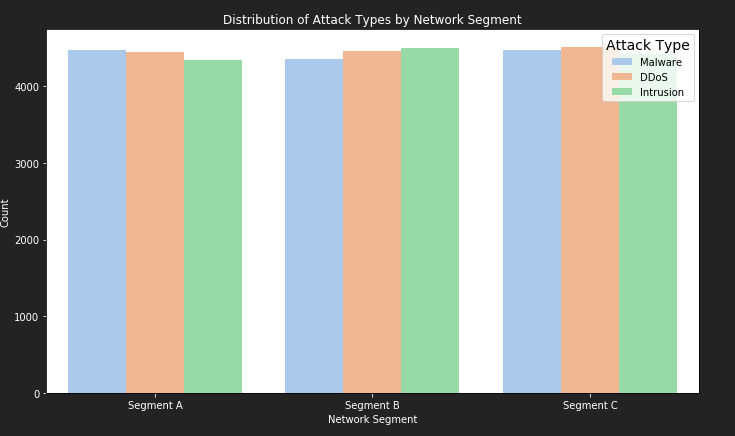
从上图中,可分析各个网段,受哪种攻击较多
a类网段受malware攻击较多
b类网段受intrusion攻击较多
c类网段三种攻击接近持平
流量类型分类
分析不同类型的网络流量(如 HTTP, DNS 等)在数据集中的分布。
流量类型分布
# 统计每种流量类型的频率
traffic_type_counts = dataset_cleaned['Traffic Type'].value_counts().reset_index().rename(columns={'index': 'Traffic Type', 'Traffic Type': 'Count'})
# 创建流量类型的条形图
plt.figure(figsize=(12, 6))
sns.barplot(x='Traffic Type', y='Count', data=traffic_type_counts, palette='coolwarm')
plt.title('Distribution of Traffic Types')
plt.show()
额……出来的条形图怎么肉眼有点看不出区别呀 ̄□ ̄|| 有点尴尬,
这时候,想到的就是三种类型的count差异不大,这时候就添加如下代码
# 添加具体数值标签
for p in ax.patches:
ax.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='baseline')
# 代码解释
# ax.patches 是一个包含所有图形元素的列表
# ax.annotate内部参数
# 参数1,使用f-string将条形的高度转换为整数,并将其作为文本显示。
# 参数2,将文本标签放在条形的中间位置,高度为p.get_height()
# 参数3,对齐方式 ha水平 va垂直
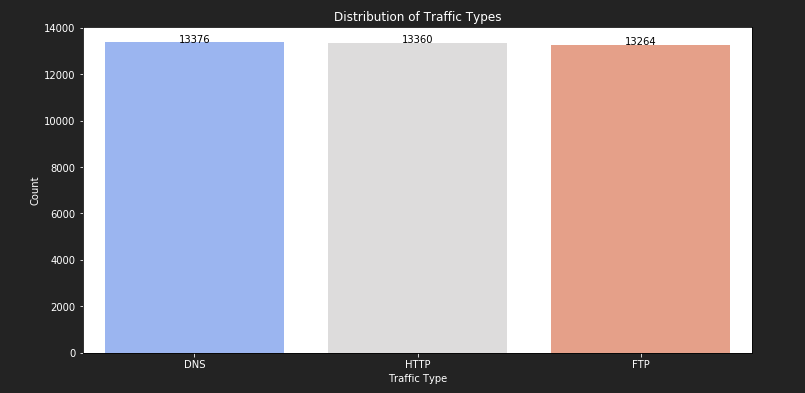
这时候,条形统计图,每个柱体上都有清晰的数值大小,从图和数值可以看出,DNS流量是最常见的,其次是 HTTP,最后便是ftp。
# 设置标题颜色为白色
plt.title('Distribution of Traffic Types', color='white')
# 设置x轴标签和颜色
plt.xlabel('Traffic Type', color='white')
# 设置y轴标签和颜色
plt.ylabel('Count', color='white')
# 设置坐标轴刻度标签颜色为白色
plt.tick_params(axis='x', colors='white')
plt.tick_params(axis='y', colors='white')
前三特征总结
通过分析,得出了以下几点:
- 热图分析: 识别了出现次数最多的前 10 个源和目的 IP 地址。
- 攻击特征与类型: 受最多的类型攻击为ddos攻击,流量特征方面需持续监控。
- 流量类型: DNS 是最常见的流量类型,这可能意味着大多数网络活动是 DNS 查询或域名解析。
基于这些信息:
- 关注高频 IP 地址:识别出现次数最多的前 10 个源和目的 IP 地址,并对这些 IP 地址进行进一步的监控或安全审查。这有助于提高对可能存在的潜在威胁的感知,并采取必要的行动。
- 持续监控数据以识别潜在的恶意活动:维持对网络流量的持续监控,使用威胁情报和异常检测系统来识别任何可能的恶意活动。通过实时监测和分析数据,可以及早发现和应对潜在的威胁,确保网络的安全性。
- 优化网络性能和安全措施,特别是针对 DNS 流量:基于对 DNS 流量的分析,对网络进行优化和强化安全措施。例如,确保 DNS 服务器的稳定性和高可用性,优化 DNS 解析速度,防止 DNS 劫持等。
其他特征分析
异常检测
# 基于“异常分数”字段的异常检测,通常,离平均值3个标准差被认为是异常
anomaly_threshold = dataset['Anomaly Scores'].mean() + 3 * dataset['Anomaly Scores'].std()
anomalies = dataset[dataset['Anomaly Scores'] > anomaly_threshold]
# 异常计数
anomaly_count = anomalies.shape[0]
# 异常的基本细节
anomalies_details = anomalies[['Timestamp', 'Source IP Address', 'Destination IP Address', 'Source Port', 'Destination Port', 'Protocol', 'Anomaly Scores']].head()
anomaly_count, anomalies_details # 输出
(0,
Empty DataFrame
Columns: [Timestamp, Source IP Address, Destination IP Address, Source Port, Destination Port, Protocol, Anomaly Scores]
Index: [])根据“异常分数”字段进行的异常检测的输出,没有检测到超过阈值的异常流量。这个阈值是基于异常分数的平均值加上三倍的标准偏差计算。
协议分析
# 协议分析:确定最常用的协议,并检查任何非标准协议
# 计算每个协议的出现次数
protocol_counts = data['Protocol'].value_counts()
# 计算每个协议的出现次数
standard_protocols = ['TCP', 'UDP', 'ICMP', 'HTTP', 'HTTPS', 'FTP', 'SSH', 'TELNET', 'SMTP', 'DNS']
non_standard_protocols = protocol_counts[~protocol_counts.index.isin(standard_protocols)]
protocol_counts, non_standard_protocols
# 输出
(ICMP 13429
UDP 13299
TCP 13272
Name: Protocol, dtype: int64,
Series([], Name: Protocol, dtype: int64))输出结果显示,此数据集中最常见的协议是 ICMP、UDP 和 TCP。没有检测到任何非标准协议。
威胁情报对接分析
# 威胁情报匹配:检查来自已知恶意IP地址的流量,检查“恶意软件指示器”字段是否包含任何非空值
malware_indicators_exists = dataset['Malware Indicators'].notna().any()
# 如果有恶意软件的迹象,我们过滤这些记录
malicious_traffic = pd.DataFrame()
if malware_indicators_exists:
malicious_traffic = dataset[dataset['Malware Indicators'].notna()]
# 恶意流量记录计数
malicious_count = malicious_traffic.shape[0]
# 恶意流量的基本细节,如果存在的话
malicious_details = pd.DataFrame()
if not malicious_traffic.empty:
malicious_details = malicious_traffic[['Timestamp', 'Source IP Address', 'Malware Indicators']].head()
malware_indicators_exists, malicious_count, malicious_details
# 输出
(True,
20000,
Timestamp Source IP Address Malware Indicators
0 2023-05-30 06:33:58 103.216.15.12 IoC Detected
1 2020-08-26 07:08:30 78.199.217.198 IoC Detected
2 2022-11-13 08:23:25 63.79.210.48 IoC Detected
7 2023-02-12 07:13:17 11.48.99.245 IoC Detected
8 2023-06-27 11:02:56 49.32.208.167 IoC Detected)威胁情报对接分析显示,“恶意软件指标”字段中确实存在非空值。总共有 20,000 条记录显示了恶意活动的迹象(指标为 “IoC Detected”)
端口使用分析
# 分析“源端口”和“目的端口”,以了解最活跃的端口
source_port_counts = dataset['Source Port'].value_counts()
destination_port_counts = dataset['Destination Port'].value_counts()
# 结合计数进行全面概述
combined_port_counts = source_port_counts.add(destination_port_counts, fill_value=0)
# 最活跃的5个端口
top_ports = combined_port_counts.nlargest(5)
# 检查任何不常见但开放的端口(如果端口少于5条记录,则端口不常见)
uncommon_ports = combined_port_counts[combined_port_counts < 5]
top_ports, uncommon_ports
# 输出
(1547 7.0
3120 7.0
8653 7.0
10530 7.0
14155 7.0
dtype: float64,
1024 1.0
1025 1.0
1027 1.0
1028 2.0
1029 1.0
...
65529 1.0
65530 2.0
65532 1.0
65534 2.0
65535 2.0
Length: 45321, dtype: float64)通过输出数据:
- 最活跃的端口是 1547、3120、8653、10530 和 14155,每个端口都有 7 个条目(源端口和目的端口的组合)表明这些端口频繁用于网络通信。。
- 有大量不常用但开放的端口,每个端口的记录少于 5 条。这可能表明网络中有大量不常用的开放端口,这种情况可能会增加网络的安全风险,因为攻击者可能会利用这些少见的开放端口进行攻击。
设备类型分析
import re
# 从“设备信息”中提取设备类型
device_info = dataset['Device Information']
# 根据用户代理字符串中的常见类型对设备进行分类
device_types = {
'Windows': device_info.str.contains('Windows', flags=re.IGNORECASE, regex=True).sum(),
'Mac': device_info.str.contains('Mac', flags=re.IGNORECASE, regex=True).sum(),
'Linux': device_info.str.contains('Linux', flags=re.IGNORECASE, regex=True).sum(),
'Mobile': device_info.str.contains('Mobile|Android|iPhone|BlackBerry', flags=re.IGNORECASE, regex=True).sum(),
'Other': device_info.str.contains('bot|crawler|spider|robot|cURL|python|java', flags=re.IGNORECASE, regex=True).sum()
}
# 确定最常见的设备类型
most_common_device = max(device_types, key=device_types.get)
most_common_device, device_types
# 输出
('Windows',
{'Windows': 17953, 'Mac': 11587, 'Linux': 8840, 'Mobile': 9063, 'Other': 0})通过输出数据分析:
“Windows” 设备是最常见的,共有 17,953 个条目。
其次是 “Mac” 设备,有 11,587 个条目。
“Mobile” 设备(包括 Android、iPhone 和 BlackBerry)有 9,063 个条目。
“Linux” 设备有 8,840 个条目。
没有检测到明显的爬虫或机器人流量(如 bot、crawler、spider、robot、cURL、python、java 等)。
Windows 设备在网络中最为常见,其次是 Mac 和移动设备,对于设备的差异, 可以分析不同设备类型的用户行为差异
这些数据可能并不全面,鉴于设备类型是通过用户代理字符串中的关键词进行分类的,而这些字符串可以被修改或伪造。
用户-应用行为分析
数据集中没有直接关于应用类型的字段,可以根据其他相关字段(如 “设备信息”、”目的 IP 地址” 或 “协议”)进行推断。
# 提取应用程序数据
app_data_exists = dataset['Device Information'].str.contains('MSIE|Firefox|Chrome|Safari|Edge|Opera', flags=re.IGNORECASE, regex=True).any()
# 如果应用数据存在,则对其进行分类
app_data = {}
if app_data_exists:
app_data = {
'MSIE': device_info.str.contains('MSIE', flags=re.IGNORECASE, regex=True).sum(),
'Firefox': device_info.str.contains('Firefox', flags=re.IGNORECASE, regex=True).sum(),
'Chrome': device_info.str.contains('Chrome', flags=re.IGNORECASE, regex=True).sum(),
'Safari': device_info.str.contains('Safari', regex=True).sum(), # Safari字符串也是Chrome UA的一部分,区分大小写匹配
'Edge': device_info.str.contains('Edge', flags=re.IGNORECASE, regex=True).sum(),
'Opera': device_info.str.contains('Opera', flags=re.IGNORECASE, regex=True).sum(),
}
# 检测是否可以继续进行用户应用程序行为分析
can_proceed_with_user_app_analysis = 'User Information' in dataset.columns and app_data_exists
app_data_exists, app_data, can_proceed_with_user_app_analysis从 “设备信息” 字段中提取应用数据,并且数据集中包含 “用户信息” 字段,由此可以进行用户-应用行为分析。分析哪些用户更倾向于使用哪种类型的浏览器。
# 根据应用程序数据添加一个新列'Browser'
browsers = ['MSIE', 'Firefox', 'Chrome', 'Safari', 'Edge', 'Opera']
for browser in browsers:
dataset.loc[dataset['Device Information'].str.contains(browser, case=False), 'Browser'] = browser
# 因为'Safari'字符串也是'Chrome'用户代理的一部分,需要专门处理这种数据
dataset.loc[dataset['Device Information'].str.contains('Chrome', case=False) &
~dataset['Device Information'].str.contains('Edge', case=False), 'Browser'] = 'Chrome'
dataset.loc[dataset['Device Information'].str.contains('Safari', case=False) &
~dataset['Device Information'].str.contains('Chrome', case=False), 'Browser'] = 'Safari'
# 分析哪些用户正在使用哪些浏览器
user_browser = dataset.groupby('User Information')['Browser'].apply(lambda x: x.mode().iloc[0] if not x.mode().empty else None)
# 每种浏览器类型的前5名用户
top_users_per_browser = user_browser.value_counts().nlargest(5)
# 准备最终结果
user_app_behavior = user_browser.reset_index().groupby('Browser')['User Information'].apply(list).to_dict()
top_users = top_users_per_browser.to_dict()
top_users, {k: v[:5] for k, v in user_app_behavior.items()} # 由于空间限制,每个类别只显示前5个用户
# 输出,该结果已进行每种浏览器类型的用户数量排序,并输出每种浏览器类型的前5名用户列表,对于可视化,看情况而定,这里再做个饼图分析占比
({'Safari': 7725,
'MSIE': 6643,
'Opera': 6169,
'Chrome': 6159,
'Firefox': 5693},
{'Chrome': ['Aaina Babu',
'Aaina Bala',
'Aaina Bath',
'Aaina Desai',
'Aaina Deshpande'],
'Firefox': ['Aaina Bal',
'Aaina Baria',
'Aaina Bedi',
'Aaina Behl',
'Aaina Chana'],
'MSIE': ['Aaina Arya',
'Aaina Balasubramanian',
'Aaina Bansal',
'Aaina Bhatia',
'Aaina Biswas'],
'Opera': ['Aaina Ahluwalia',
'Aaina Bahri',
'Aaina Bakshi',
'Aaina Batta',
'Aaina Bhatti'],
'Safari': ['Aaina Bahl',
'Aaina Balan',
'Aaina Bhargava',
'Aaina Choudhury',
'Aaina Dada']})import matplotlib.pyplot as plt
# 浏览器类型及其用户数量数据
browser_data = {
'Safari': 7725,
'MSIE': 6643,
'Opera': 6169,
'Chrome': 6159,
'Firefox': 5693
}
# 饼图标签(浏览器类型)
labels = browser_data.keys()
# 饼图数据(用户数量)
sizes = browser_data.values()
# 绘制饼图
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
# 添加标题
plt.title("Browser Users Distribution",color='white')
# 显示图表
plt.show()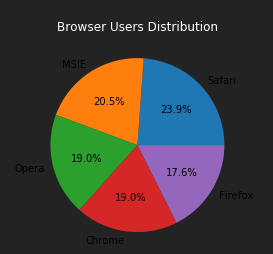
分析结果:
- 这个样本中,Safari 浏览器拥有最多的用户数量,占总用户数量的 23.9%。
- 排名第二的是 MSIE 浏览器,占20.5%;并排第三的是 Opera、 Chrome浏览器,占 19.0%。
- Firefox 浏览器的用户数量占比最低。
总结
通过该数据集,针对不同的特征,做对应的分析,深入了解网络安全威胁的特征和趋势,并从中获取有价值的见解。这样的分析有助于我们更好地理解攻击者的策略和技术,从而能够采取有效的预防和应对措施来保护我们的数字环境。 当然,针对数据的来源于具体的业务方向,可以更加深入,有针对性的分析,以发掘更好的价值。
附录
数据来源:kaggle社区公开数据集
文中代码与csv数据集: https://bevis.lanzouq.com/i28Ci1c0eb9i (文章代码与数据集放压缩包了)




